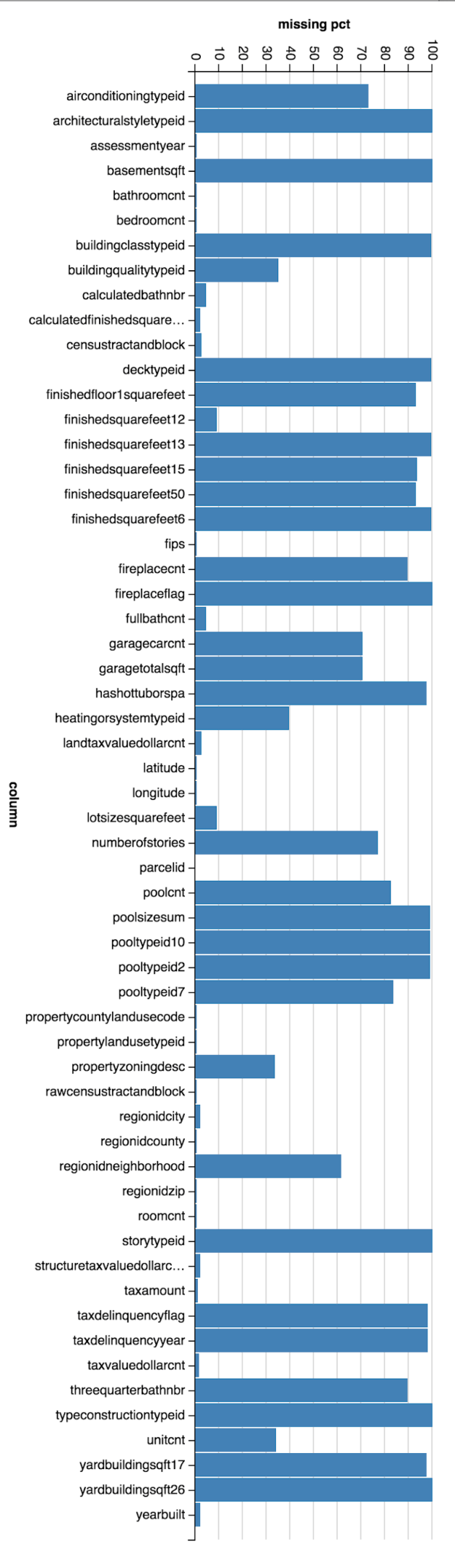
With the release of Spark 2.2.0, we can now use the newly implemented Imputer to replace missing values in our dataset. However, it only supports mean and median as the imputation strategies currently but not the most frequent. The default strategy is mean. (Note: scikit-learn provides all three different strategies).
See the Imputer class and the associated Jira ticket below
https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark/ml/feature/Imputer.scala
https://issues.apache.org/jira/browse/SPARK-13568
Example usage using Zillow Price Kaggle dataset:
val imputer = new Imputer()
imputer.setInputCols(Array("bedroomcnt", "bathroomcnt", "roomcnt", "calculatedfinishedsquarefeet", "taxamount", "taxvaluedollarcnt", "landtaxvaluedollarcnt", "structuretaxvaluedollarcnt"))
imputer.setOutputCols(Array("bedroomcnt_out", "bathroomcnt_out", "roomcnt_out", "calculatedfinishedsquarefeet_out", "taxamount_out", "taxvaluedollarcnt_out", "landtaxvaluedollarcnt_out", "structuretaxvaluedollarcnt_out"))
However, I ran into this issue, it can’t handle column values of integer type. See this Jira ticket.
https://issues.apache.org/jira/browse/SPARK-20604
The good news is a pull request was created to fix the issue by converting integer type to double type during imputation. See the pull request below.