InstaCart has recently organized a Kaggle competition and published anonymized data on customer orders over time to predict which previously purchased products will be in a user’s next order. You can check out the link below.
https://www.kaggle.com/c/instacart-market-basket-analysis
First, I used Spark to analyze the data to uncover hidden insights.
We were given the departments data

Products data

Orders data

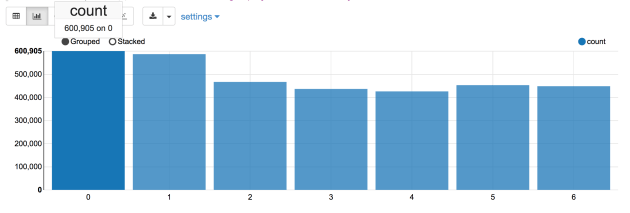
Lets find out which is the busiest day of the week. As it turns out, day 0 is the busiest day, with 600,905 orders followed by day 1 with 587478 orders. I would assume day 0 is Sunday and day 1 is Monday.
Next, lets figure out which is the busiest hour in a day. It turns out 10 am is the busiest hour with 288,418 orders, followed by 11 am with 284,728 orders.
As you can see, Instacart customers like to shop from 11 am to 5 pm. It would be interesting to see the day of week + hour of day breakdown too.

Here is the breakdown of popular hours for each day. 10 am dominates the top spot.

Next lets figure out the top ten popular items among Instacart customers. Surprisingly, banana is the most popular item.

Lets find out the top item for each department. We can see that Blueberries is the most popular item for frozen department and Extra Virgin Olive Oil is the most popular item for pantry department. Some unexpected surprises are dried mango, cotton swabs, and honey nut cheerios.

We are also interested in knowing the reorder interval, how many days since the prior order before making the next order.

As we discovered, 30 days is the most frequent reorder interval. It looks like most of customers reorder once a month. On the other hand, 320,608 orders were placed after 7 days since the prior order. We can concluded that majority of customers reorder after 1 month or 1 week since the prior order.
Stay tuned for next blog on my study results at the individual user level.