To understand HyperLogLog (HLL), one should read the LogLog and HyperLogLog papers.
http://algo.inria.fr/flajolet/Publications/DuFl03-LNCS.pdf (LogLog)
http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf (HyperLogLog)
The major difference between the two is one uses regular mean and the other (HLL) uses harmonic mean to average the estimate cardinality calculated by different m buckets. I would view these buckets as different experiments.
The accuracy (standard error) is controlled by the number of buckets, m. The more buckets the better is the estimation. But, HLL has better accuracy compared to LogLog given the same number of buckets.
The standard error for HLL is

The standard error for LogLog is
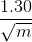
The following is the LogLog algorithm taken from the paper

Basically, there are m buckets, each one is keeping track of the run of consecutive zeros in the bit string. We then figure out the max run of consecutive zeros (position of leftmost 1) in all the buckets.
eg. 1 => 1, 001 =>3
Then using the cardinality estimate formula shown in the last line, calculate the estimate unique counts. As you see from the formula, it involves taking the average of the run of zeros observed in these buckets. (Note: the alpha is the bias correction applied to the cardinality estimate)
For HyperLogLog, instead of using the average, harmonic mean (stochastic averaging) is used. Please refer to the HLL paper for more detailed description of the formula.
Taken from the HLL paper,






