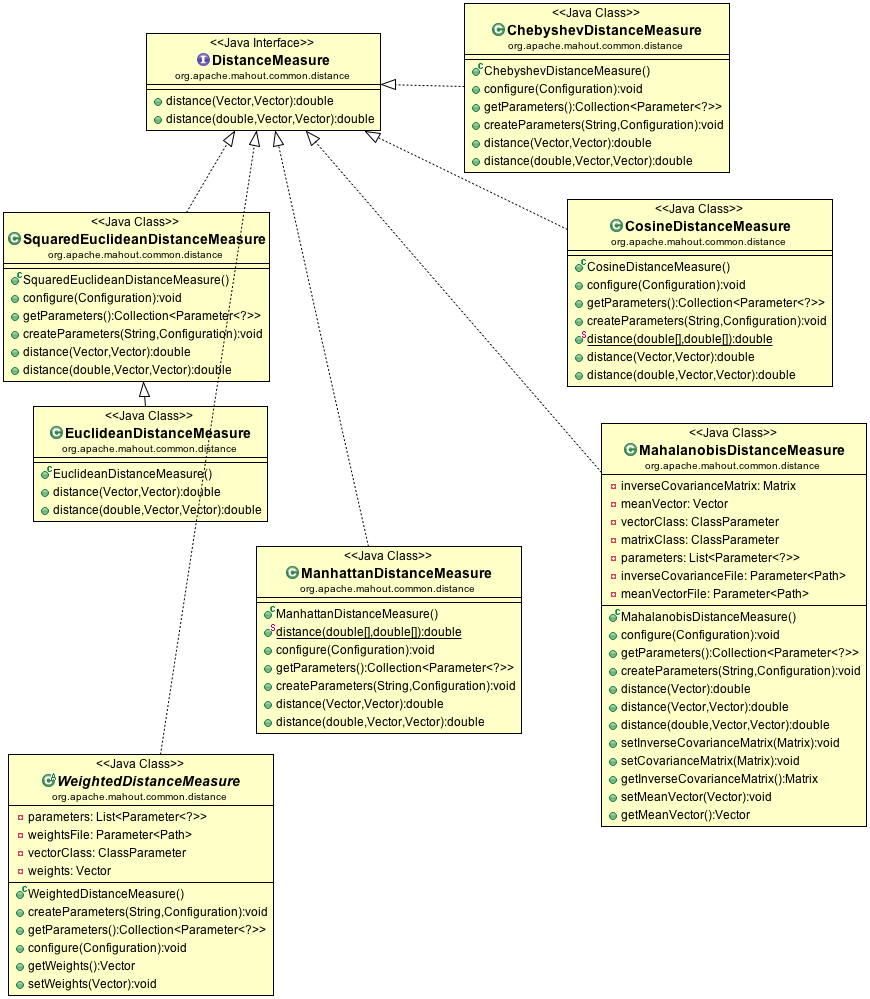
I was looking into Mahout Math package especially the various Vector implementations, such as DenseVector, NamedVector, WeightedVector, and etc. Here is the class diagram.

mahout math Vector class diagram
Vector is the base interface for all different Vector implementations. There is a base abstract class, AbstractVector which provides the base implementations of some defined methods, such as norm, normalize, logNormalize, getDistanceSquared, maxValue, minValue, plus, minus, times and etc in the interface.
There are a few interesting methods in the AbstractVector. Eg. createOptimizedCopy(Vector vector)
</pre>
private static Vector createOptimizedCopy(Vector vector) {
Vector result;
if (vector.isDense()) {
result = vector.like().assign(vector, Functions.SECOND_LEFT_ZERO);
} else {
result = vector.clone();
}
return result;
}
ConstantVector implementation is also quite interesting. Since it is a vector of size n with a constant value, it only has a int size member and double value member.
As the name implies, DenseVector is an implementation of a dense vector. It contains an array of double internally. It also provides NonDefaultIterator and AllIterator which implement Iterator interface to allow for each type operation. NonDefaultIterator iterates through non zeros elements whereas AllIterator iterates through all elements.
DelegatingVector implements the Vector interface without extending the AbstractVector. It has a Vector as a delegate internally. WeightedVector extends DelegatingVector and decorate the delegate with a weight and positional index.
</pre>
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.mahout.math;
import org.apache.mahout.math.function.DoubleDoubleFunction;
import org.apache.mahout.math.function.DoubleFunction;
/**
* The basic interface including numerous convenience functions <p/> NOTE: All implementing classes must have a
* constructor that takes an int for cardinality and a no-arg constructor that can be used for marshalling the Writable
* instance <p/> NOTE: Implementations may choose to reuse the Vector.Element in the Iterable methods
*/
public interface Vector extends Cloneable {
/** @return a formatted String suitable for output */
String asFormatString();
/**
* Assign the value to all elements of the receiver
*
* @param value a double value
* @return the modified receiver
*/
Vector assign(double value);
/**
* Assign the values to the receiver
*
* @param values a double[] of values
* @return the modified receiver
* @throws CardinalityException if the cardinalities differ
*/
Vector assign(double[] values);
/**
* Assign the other vector values to the receiver
*
* @param other a Vector
* @return the modified receiver
* @throws CardinalityException if the cardinalities differ
*/
Vector assign(Vector other);
/**
* Apply the function to each element of the receiver
*
* @param function a DoubleFunction to apply
* @return the modified receiver
*/
Vector assign(DoubleFunction function);
/**
* Apply the function to each element of the receiver and the corresponding element of the other argument
*
* @param other a Vector containing the second arguments to the function
* @param function a DoubleDoubleFunction to apply
* @return the modified receiver
* @throws CardinalityException if the cardinalities differ
*/
Vector assign(Vector other, DoubleDoubleFunction function);
/**
* Apply the function to each element of the receiver, using the y value as the second argument of the
* DoubleDoubleFunction
*
* @param f a DoubleDoubleFunction to be applied
* @param y a double value to be argument to the function
* @return the modified receiver
*/
Vector assign(DoubleDoubleFunction f, double y);
/**
* Return the cardinality of the recipient (the maximum number of values)
*
* @return an int
*/
int size();
/**
* @return true iff this implementation should be considered dense -- that it explicitly
* represents every value
*/
boolean isDense();
/**
* @return true iff this implementation should be considered to be iterable in index order in an efficient way.
* In particular this implies that {@link #all()} and {@link #nonZeroes()} ()} return elements
* in ascending order by index.
*/
boolean isSequentialAccess();
/**
* Return a copy of the recipient
*
* @return a new Vector
*/
@SuppressWarnings("CloneDoesntDeclareCloneNotSupportedException")
Vector clone();
Iterable<Element> all();
Iterable<Element> nonZeroes();
/**
* Return an object of Vector.Element representing an element of this Vector. Useful when designing new iterator
* types.
*
* @param index Index of the Vector.Element required
* @return The Vector.Element Object
*/
Element getElement(int index);
/**
* Merge a set of (index, value) pairs into the vector.
* @param updates an ordered mapping of indices to values to be merged in.
*/
void mergeUpdates(OrderedIntDoubleMapping updates);
/**
* A holder for information about a specific item in the Vector. <p/> When using with an Iterator, the implementation
* may choose to reuse this element, so you may need to make a copy if you want to keep it
*/
interface Element {
/** @return the value of this vector element. */
double get();
/** @return the index of this vector element. */
int index();
/** @param value Set the current element to value. */
void set(double value);
}
/**
* Return a new vector containing the values of the recipient divided by the argument
*
* @param x a double value
* @return a new Vector
*/
Vector divide(double x);
/**
* Return the dot product of the recipient and the argument
*
* @param x a Vector
* @return a new Vector
* @throws CardinalityException if the cardinalities differ
*/
double dot(Vector x);
/**
* Return the value at the given index
*
* @param index an int index
* @return the double at the index
* @throws IndexException if the index is out of bounds
*/
double get(int index);
/**
* Return the value at the given index, without checking bounds
*
* @param index an int index
* @return the double at the index
*/
double getQuick(int index);
/**
* Return an empty vector of the same underlying class as the receiver
*
* @return a Vector
*/
Vector like();
/**
* Return a new vector containing the element by element difference of the recipient and the argument
*
* @param x a Vector
* @return a new Vector
* @throws CardinalityException if the cardinalities differ
*/
Vector minus(Vector x);
/**
* Return a new vector containing the normalized (L_2 norm) values of the recipient
*
* @return a new Vector
*/
Vector normalize();
/**
* Return a new Vector containing the normalized (L_power norm) values of the recipient. <p/> See
* http://en.wikipedia.org/wiki/Lp_space <p/> Technically, when 0 < power < 1, we don't have a norm, just a metric,
* but we'll overload this here. <p/> Also supports power == 0 (number of non-zero elements) and power = {@link
* Double#POSITIVE_INFINITY} (max element). Again, see the Wikipedia page for more info
*
* @param power The power to use. Must be >= 0. May also be {@link Double#POSITIVE_INFINITY}. See the Wikipedia link
* for more on this.
* @return a new Vector x such that norm(x, power) == 1
*/
Vector normalize(double power);
/**
* Return a new vector containing the log(1 + entry)/ L_2 norm values of the recipient
*
* @return a new Vector
*/
Vector logNormalize();
/**
* Return a new Vector with a normalized value calculated as log_power(1 + entry)/ L_power norm. <p/>
*
* @param power The power to use. Must be > 1. Cannot be {@link Double#POSITIVE_INFINITY}.
* @return a new Vector
*/
Vector logNormalize(double power);
/**
* Return the k-norm of the vector. <p/> See http://en.wikipedia.org/wiki/Lp_space <p/> Technically, when 0 > power
* < 1, we don't have a norm, just a metric, but we'll overload this here. Also supports power == 0 (number of
* non-zero elements) and power = {@link Double#POSITIVE_INFINITY} (max element). Again, see the Wikipedia page for
* more info.
*
* @param power The power to use.
* @see #normalize(double)
*/
double norm(double power);
/** @return The minimum value in the Vector */
double minValue();
/** @return The index of the minimum value */
int minValueIndex();
/** @return The maximum value in the Vector */
double maxValue();
/** @return The index of the maximum value */
int maxValueIndex();
/**
* Return a new vector containing the sum of each value of the recipient and the argument
*
* @param x a double
* @return a new Vector
*/
Vector plus(double x);
/**
* Return a new vector containing the element by element sum of the recipient and the argument
*
* @param x a Vector
* @return a new Vector
* @throws CardinalityException if the cardinalities differ
*/
Vector plus(Vector x);
/**
* Set the value at the given index
*
* @param index an int index into the receiver
* @param value a double value to set
* @throws IndexException if the index is out of bounds
*/
void set(int index, double value);
/**
* Set the value at the given index, without checking bounds
*
* @param index an int index into the receiver
* @param value a double value to set
*/
void setQuick(int index, double value);
/**
* Increment the value at the given index by the given value.
*
* @param index an int index into the receiver
* @param increment sets the value at the given index to value + increment;
*/
void incrementQuick(int index, double increment);
/**
* Return the number of values in the recipient which are not the default value. For instance, for a
* sparse vector, this would be the number of non-zero values.
*
* @return an int
*/
int getNumNondefaultElements();
/**
* Return the number of non zero elements in the vector.
*
* @return an int
*/
int getNumNonZeroElements();
/**
* Return a new vector containing the product of each value of the recipient and the argument
*
* @param x a double argument
* @return a new Vector
*/
Vector times(double x);
/**
* Return a new vector containing the element-wise product of the recipient and the argument
*
* @param x a Vector argument
* @return a new Vector
* @throws CardinalityException if the cardinalities differ
*/
Vector times(Vector x);
/**
* Return a new vector containing the subset of the recipient
*
* @param offset an int offset into the receiver
* @param length the cardinality of the desired result
* @return a new Vector
* @throws CardinalityException if the length is greater than the cardinality of the receiver
* @throws IndexException if the offset is negative or the offset+length is outside of the receiver
*/
Vector viewPart(int offset, int length);
/**
* Return the sum of all the elements of the receiver
*
* @return a double
*/
double zSum();
/**
* Return the cross product of the receiver and the other vector
*
* @param other another Vector
* @return a Matrix
*/
Matrix cross(Vector other);
/*
* Need stories for these but keeping them here for now.
*/
// void getNonZeros(IntArrayList jx, DoubleArrayList values);
// void foreachNonZero(IntDoubleFunction f);
// DoubleDoubleFunction map);
// NewVector assign(Vector y, DoubleDoubleFunction function, IntArrayList
// nonZeroIndexes);
/**
* Examples speak louder than words: aggregate(plus, pow(2)) is another way to say
* getLengthSquared(), aggregate(max, abs) is norm(Double.POSITIVE_INFINITY). To sum all of the positive values,
* aggregate(plus, max(0)).
* @param aggregator used to combine the current value of the aggregation with the result of map.apply(nextValue)
* @param map a function to apply to each element of the vector in turn before passing to the aggregator
* @return the final aggregation
*/
double aggregate(DoubleDoubleFunction aggregator, DoubleFunction map);
/**
* <p>Generalized inner product - take two vectors, iterate over them both, using the combiner to combine together
* (and possibly map in some way) each pair of values, which are then aggregated with the previous accumulated
* value in the combiner.</p>
* <p>
* Example: dot(other) could be expressed as aggregate(other, Plus, Times), and kernelized inner products (which
* are symmetric on the indices) work similarly.
* @param other a vector to aggregate in combination with
* @param aggregator function we're aggregating with; fa
* @param combiner function we're combining with; fc
* @return the final aggregation; if r0 = fc(this[0], other[0]), ri = fa(r_{i-1}, fc(this[i], other[i]))
* for all i > 0
*/
double aggregate(Vector other, DoubleDoubleFunction aggregator, DoubleDoubleFunction combiner);
/** Return the sum of squares of all elements in the vector. Square root of this value is the length of the vector. */
double getLengthSquared();
/** Get the square of the distance between this vector and the other vector. */
double getDistanceSquared(Vector v);
/**
* Gets an estimate of the cost (in number of operations) it takes to lookup a random element in this vector.
*/
double getLookupCost();
/**
* Gets an estimate of the cost (in number of operations) it takes to advance an iterator through the nonzero
* elements of this vector.
*/
double getIteratorAdvanceCost();
/**
* Return true iff adding a new (nonzero) element takes constant time for this vector.
*/
boolean isAddConstantTime();
}